Sorry AI, APIs Are for Humans
Net API Notes for 2023/03/07 - Issue 211
In recent newsletters, I've described my experiences creating an OpenAPI description with the help of GitHub Copilot and ChatGPT "AI". In both cases, I've been impressed with the potential. But is there a scenario in the near future where a sufficiently Large Language Model (LLM) will obsolete API designers? Are API engineers going to be out of a job if an LLM can generate code from any sufficiently well-written OpenAPI description? Are we all a significant version update away from turning in our API designer dog tags and starting over at prompt engineering boot camp?
I'll explore those issues with the designers’ future toolbox and more in this edition of Net API Notes.

Will AI Replace API Designers?
TL;DR:
No, in the same way, auto-generating an API from a data model has never become a serious development option: successful API design that aspires to be more than point-to-point integrations requires intuition, stakeholder engagement, and creative synthesis. While the current LLM crop is another input source, they lack the "human touch" we associate with good design. After all, as counter-intuitive as it may seem, we build APIs for humans.
Further, the amount of writing acumen needed to coax desired results from an LLM happens to be the same kind of communication skills already sorely lacking. Turning abstract technical concepts into succinct, clear directives remains a rare industry skill regardless of we're talking to people or machines.
Longer Explanation
AI Is The Latest Obsession In The Search for the Next Internet-Level Event
New technologies follow a sigmoid, or "S", curve - things start slow as the technologies are introduced, and major barriers to usage are hammered out. Then, there is explosive growth as increasing numbers of people begin using the technology to do practical, useful things. These things, in turn, create new, bigger, better things that people keep making more stuff with. Then, as you reach a limit with the technology, there is a plateau, and the rate of progress flattens out again. Just think about the iPhone; there's a reason people no longer camp out overnight for a new release.
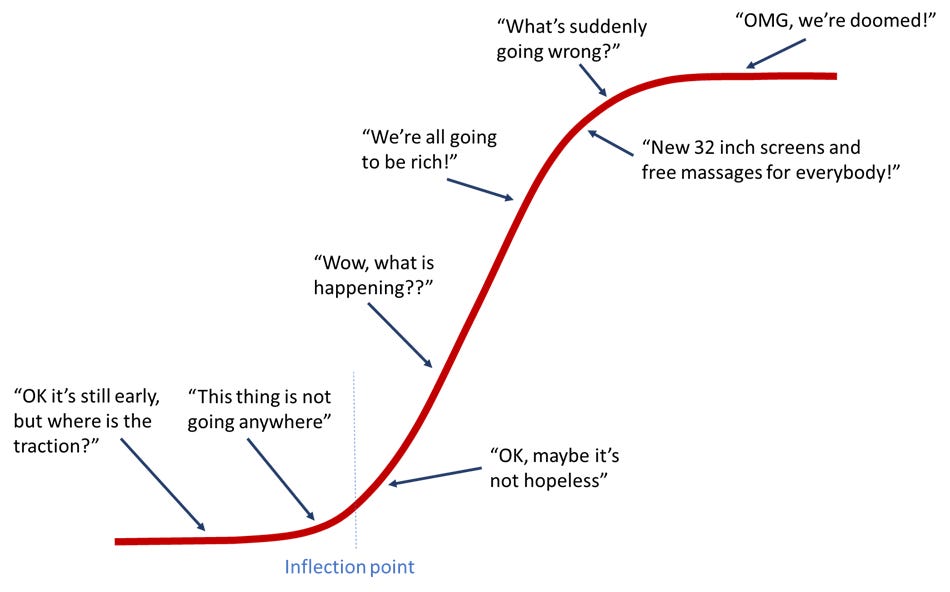
It's been awhile since we've seen a sigmoid curve in software. The waves caused by the internet and WWW continue to rock industries decades after landing. The period in the later aughts was also particularly disruptive with the triune of cloud compute and storage (AWS, 2006), social media (Facebook, 2006 and Twitter, 2007), and smartphones (iPhone, 2007 and Android, 2008) (or a goosing of compute, data, and mobility). Underpinning all of these is a proliferation of web-based API architectures, an interconnect preference that continues to butter the bread for a vast majority of this newsletter's readers.
Lots and lots and lots of other efforts since have laid claim to be the next big thing - from IoT to voice assistants, from blockchain-based schemes like NFTs to Web 3 (which I briefly touched on) - all have attempted to woo talent, tech press, and investment dollars with promises of the next curve. The tell-tale difference between a technology undergoing a real sigmoid curve transition is when a massive number of people - not just the early adopters - find value to do things meaningful with the technology, not just grasp at a speculative investment.
Setting aside the ethical questions, from composing difficult emails to summarizing vast amounts of text in seconds, from brainstorming workshop outlines to cheating at essay writing, people are using LLMs like ChatGPT to do real stuff. And, as long as the service is available and not overwhelmed by the crush of traffic, anybody can use the technology.
Text transformers and diffusion models are on a sigmoid curve of progress. So what is to stop your cost-conscious director from replacing expensive API practitioners with the output from a text prompt?
Good APIs Are More Than The Sum of Their Bits
"Software making is often billed as a bastion of logic and theory, because computers work that way. But making software isn't software." - GeePaw Hill
When we think about how API design is done, we may envision a brilliant tech lead, solutions architect, or passionate product manager sitting down at that laptop. With grim determination, they wrestle OpenAPI components from the void for interfaces to support "software engineering on the scale of decades". This individual (or team) "writes" the interface into existence.
Despite what many online tutorials and YouTube videos may lead you to believe, however, an API doesn't emerge from a vacuum. What differentiates a good API from automated attempts is the degree to which the API designer studies what came before, engages with stakeholders, comprehends the requirement constraints, balances tradeoffs, and incorporates learnings. Good API design (and the subsequent development) is a job not of writing, but of synthesis.
Both writing code and synthesis are capable of creating an addressable endpoint. However, synthesis is different from writing. The programmatic part - the part we might mistake as the totality of API creation - is the easy part. And, because it is the easy part, it is prone to disruption. Synthesis, on the other hand, is a collaboration through the language of others: their words, their jobs to be done, and even their previously written code. When viewed this way, LLMs are not a replacement for API designers, but yet another source of signal in a feedback loop that good API designers are attuned to.
And it is the cycle time of this feedback loop that makes LLMs valuable to API designers.
Shortening the Synthesis Loop
Large language models, like ChatGPT, are text models that predict what word comes next. It just so turns out that following statistical probability is beneficial in a variety of situations.
An LLM like ChatGPT will output an OpenAPI description within a few seconds. The first attempt is likely to be a bit wrong but, honestly, most API designers' first attempts would be a bit wrong. Changes to that description are as simple as asking for an update and having new output arrive a few seconds later. We don't have to Google for exact syntax or comb the internal CMS for prior examples. In this manner, ChatGPT is similar to paired programming with another developer, one that you watch carefully and occasionally need to interject and correct what is unfolding. Notably, this occurs at your pace; no waiting for the partner to finish their meeting or return from lunch. Sometimes, you'll be right. Other times, through collaboration, you may learn why a different approach was taken. Faster feedback cycles ultimately result in better software.
My ability to memorize the exact syntax of the OpenAPI specification is not where I bring value to API creation. But a computer model does that well. So best to outsource that to the machine and iterate rapidly into something I can engage with others over.
Where Are We On The Curve?
Gauging where LLMs are along their sigmoid curve is something we will only know in retrospect. We've passed the inflection point. If we're coming out of the hurly-burly and about to flatten out, then cool - designers and developers have new tools to collaborate with. It will make things more efficient, provide a dependable place to bounce ideas around, and generally reduce the time spent on tedious, boilerplate bits. If instead, we're at the middle of the curve, then we're going to get some impressive new tools that will change how we approach our work; after all, we still have mechanical engineers, but we are far removed from rooms full of people hunched over drafting tables, pencils in hand.
As counter-intuitive as it may sound, APIs are written for humans. Two companies integrate with each other only after a significant amount of meat evaluates their available options. The decision includes discovery, evaluation, and a fair amount of subjective judgment. Even in cases where we're talking about inter-company communication, the relationships between people are instrumental in determining to what degree and how often interoperability occurs. The sooner we're comfortable with that concept, the sooner we place these LLMs in their proper place in our toolchains - not as a replacement but as a rapid-fire synthesis source.
Comic created by Forrest Brazeal
Milestones
- Stephen Mizell has an intriguing new e-book out, The Language-Oriented Approach to API Development
- The OWASP API Security Project announced a new 2023 release candidate is now available. I strongly recommend anybody who has anything to do with APIs check it out.
- As seen by Joyce Stack, the London borough of Hackney has an outstanding API Playbook. I previously covered Hackney and their API Platform ambitions in 2021; seeing the continued high bar they set for government service communication is great.
- Google announced Service Weaver, an open-source solution that promises to "allow you to build a monolith and deploy microservices." Many quickly pointed out that hiding the difference between RPC and local method calls is a line we've heard before (CORBA in 1991, for example). I guess those that forget the fallacies of distributed computing are doomed to re-implement them. For a case study on transforming monoliths into microservices, check out this detailed overview of how Dropbox did it.
- TikTok released an API for researchers! Academics should be able to study the impacts of social networks. Yay! However, upon closer inspection, the terms are eyebrow-raising: sending all research at least 30 days before publication and letting them license your name, logo, and research in derivative works.
- CADL, an OpenAPI alternative, "a more precise" API definition that excels at code generation, is now called TypeSpec. Interesting use cases are beginning to appear.
- Twitter is the dumpster fire that keeps burning. In addition to learning about an unpaid $70 million AWS bill this week, a configuration change blocked Twitter from its own API, causing an outage.
Wrapping Up
After the last issue, this little enterprise received its first Substack paying subscription! I've used Patreon to accept digital donations for the last several years, but still had to set up Substack's payment bits and bobs when prompted by this kind supporter. Thank you for being the gentle pants kick I needed to do that! I anticipate people will continue to prefer whatever platform they're comfortable with, so I'll continue supporting Substack and Patreon pledges going forward.
A logical question one might ask is, "What happens to the money?" Initially, the donations really were all about buying me the equivalent of a coffee each month - helping offset the caffeine consumed during early mornings and late evenings while compiling the newsletter. Over time, I've added software tools that help me produce a more polished end result:
- Grammarly for typo detection and improved clarity at $144 a year
- Midjourney for image generation to accompany the articles at $120 a year
- Code and OpenAPI research generation via Github Copilot ($10/month) and ChatGPT Plus ($20/month)
A tiny portion of this newsletter's readers not only keep the contents free for the vast majority. They also encourage the further exploration of new technologies and continued polish of the final product. Thanks to all those who help make theoretical improvements a reality for the benefit of all.
That's all for now. Till next time,
Matthew (@matthew and matthewreinbold.com)