Why Quantifying Good API Design, Even With AI, Is Not The Homerun Metric You Think It Is
Net API Notes for 2023/03/15 - Issue 212 - Measuring Quality Design
In the last issue, I talked at great length about how creating "good" API design required uniquely human skills: skills like curiosity, intuition, and humility. More than one commentator responded with a wish for a clear and concise definition of what constitutes good design. And, by extension, if we had a clarity on what good looks like, we could then, conceivably, automate the testing of it.
In this edition of Net API Notes, I'm going to discuss some of the challenges in quantifying a subjective measure, share some of my failed efforts so that you can avoid the same pitfalls, discuss a theoretical machine learning approach, and then end with a reminder on what really matters.

Quantifying "Good" - Attempting to Measure API Design Quality
The Challenge is that Good is Subjective
Some API metrics, like uptime or average response time, are easily quantifiable. However, the quality of an API design is more difficult to gauge. Is it easy to start with? Fit-for-purpose? Extensible? Intuitive? Does it follow the Principle of Least Astonishment?
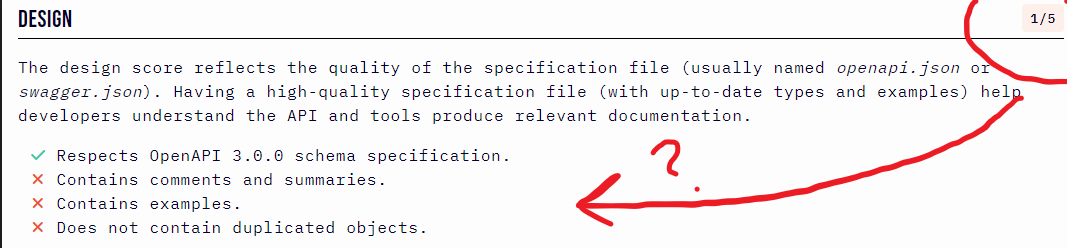
These are all desirable qualities but are hard to quantify. That hasn't stopped lots and lots of folks from trying. One of the latest is a site called APIRank.Dev. The site attempts to benchmark more than 6000 APIs in categories like Security and Reliability. One of the categories that it scores is 'Design', but tug at the thread a bit, and the comforting story quickly unravels. In the screenshots below, surely there's more than just a different OpenAPI version used?
The Medium API - Rated 4 out of 5 on Design - Retrieved March 15th

Tent House Copy - Rated 1 out of 5 on Design - Retrieved March 15th
My Own (Failed) Attempts At Quantifying Good API Design
I've led API design improvement efforts in several previous roles. In that capacity, someone in charge inevitably asks for a report showing progress on that work - ideally, a simple line chart showing design quality trending up and to the right. On the surface, it is a perfectly reasonable task. Break the water for even a second, however, and things become much less clear. What is API quality? How do we quantify it?
I covered one of my team's first considerable efforts in a 2017 API World mainstage presentation. We included several metrics of interest to our API efforts, including % of "stalled" items by a line of business (APIs that had no integrations six months or more after going into production) and % of Non-private APIs (APIs that were discoverable and available to be built upon, rather than point-to-point integrations). The design quality comprised two axes:
- API design compliance as measured by our OpenAPI linting (automatic)
- NPS, as rated by our API Center of Excellence (a manual, monthly compiling effort)
Both of these approaches had significant problems.
Adhering to the Letter, But Not the Spirit, of the API Standard
I love linting. With minimal effort, OpenAPI definition writers can have immediate feedback on how their designs can be better. Further, they do not need to learn another tool if that feedback is provided through an IDE's extension or plug-in; they can continue working in the tool they are most comfortable with.
There are limits to what linting can effectively measure, unfortunately. Linting can identify when there isn't a 'description' provided. But it can't tell if that description is good. A lot could be in a description to kickstart a new user, like I've covered before: context, disambiguation, interrelationship, values, range, or examples, and proper grammar (among other things).
External to my team, there was an attempt to improve descriptions in an automated way. We were consulted but our misgivings on their approach were overruled. This team created rules that necessitated a minimum number of words in each description, or there would be no advancement toward production.
There were lots of upset creators. With time, this same tool team had to update their checking to also throw an error when the same word was repeated; informed there was a minimum word count but not told what it was, creators began spamming the same word in their descriptions repeatedly until the minimum word count was satisfied.
More time went by. Random lines from Robert Frost poems started appearing in descriptions. The creators met the letter of the 'law'. But they had little incentive or guidance for meeting the spirit.
NPS is Hazardous to One's Health
I've talked, at length, about the problems with NPS (net promoter score) and how those problems compound for something like API quality. The only other thing I didn't mention is that leaders dislike negative scores - something that is incredibly common with how NPS computation works. An executive may be accountable for dozens, if not hundreds, of APIs in their division. Telling them they have an NPS score of "-73" for the month is little comfort, even if it is the highest among their peers. How do they make it better? Should they be worried? If their systems weren't on fire, and this reporting is the first time they're being accused of having a problem, is it really a problem?
Creating a metric and attempting to incentivize competition among rivals is an adversarial strategy. NPS and its opaqueness does little to help.
We Didn't Close the Feedback Loop
There was a lot of effort put into those NPS ratings. Each team member would go through all of the APIs submitted for review that month. We'd individually evaluate them on a set of criteria, applying our experience and expertise, give them a score, and record a set of feedback. As a group, we'd then get together and discuss our scores, paying particular attention to where we had significant differences. These places were seen as differing practices and opportunities for discussion.
The expectation was that teams interested in improving would come to us and get their feedback on what could be done better on their next API design. Some folks sought us out for those spreadsheets, but I could count them on one hand. In the years we attempted that approach, that feedback remained buried behind a hostile, confusing NPS score that the API designers had to seek out. (No shade at Excel, though, our newest eSport.)
Could we 'Machine Learn' Our Way Out Of Manual Review?
Linting is a piece of the solution, but it can't entirely evaluate whether an API design is "good" on its own. And manual collaboration with API experts is a time-consuming, bottle-necking affair on a shared resource (assuming those experts exist). Could we apply a Large Language Model (LLM), a specific type of Machine Learning, to the problem?
Reinforcement learning is, perhaps, the most straightforward machine learning approach to grok. It is excellent in situations, like games, where there is a clear winner and loser. The system then "learns", through trial and error, the optimal behavior to maximize the number of wins. That works for playing Super Mario Bros. But it wouldn't be the right approach for creating a model to detect good API design; after all, there isn't a score to maximize or a level to beat.
A different approach, called supervised learning, is also out. Supervised learning is where an algorithm is trained on a vast body of carefully prepared input data. Image recognition is often created this way. The algorithm can puzzle out the pixel features relationships consistent with a dog, cat, or stoplight from a series of labeled photos. Identifying images, though, is different from identifying good APIs. Think about the training set required: providing hundreds, if not thousands, of clearly annotated and labeled "good" examples is too labor intensive. Further, what good examples would you throw at the training process after you've exhausted the Twilio and Stripe APIs of the world?
With an LLM like ChatGPT, the goal is to create plausible, coherent text. Like our API design case, we know good output when we see it, but "good" isn't easy to express computationally. How did ChatGPT get its results?
A Theoretical Approach to an Algorithmic API Design Judge
According to this Computerphile video, the approach is reinforcement learning in conjunction with another model prepared with human feedback. That means in our theoretical approach we wouldn't worry about gathering thousands of API examples and labeling what makes them good for reinforcement learning - that's too hard. Instead, we'd present two examples of an API design attempting to do the same thing to a design expert. They would pick the better API design, and those selections would be used to train a reward model similar to that used to solve the Mario games - a system that "learns" what the expert is likely to choose.
This reward model can then be used to iteratively train the reinforcement model, not at the speed of human comprehension but at the speed of computation interactions. These feedback loops improve the results. The reinforcement learning system is getting feedback not from humans but from the model attempting to judge the output like a human. There is still a degree of human effort involved, but the nature and scale of the work are substantially different.
And then there is more iteration. Prepare several of these systems, show their output to the design expert, have them select the better designs, and use that new model as a reward model for a new batch of reinforcement learning. Repeat until the suggested designs stop improving. At that point, we'd have a reinforcement model capable of producing a "good" API design from a prompt and a reward model that can guess whether an API design in a description is "good".
If implemented, we could have a means - either by pushing a button in our IDEs or by copying/pasting into a web form - by which we are immediately told whether or not we have a good API design.
However, the results would be mostly useless.
Whether a Design Passes a "Goodness" Check Is Not The Same As Feedback
Suppose I paste in a design, click a button, and pass! Yay! I take the rest of the day off and go cross-country skiing.
However, say that my design fails. Suppose, further, that my design passing is a prerequisite for moving on to whatever next step exists in a predefined API lifecycle. My only option is to create a better design. However, an Achilles heel for these kinds of systems is that they cannot describe what problematic aspects of a design exist or how to make them better. In fact, the algorithm doesn't even "know" what an API is. All it understands is it has a particular set of weights and statistical probabilities among its thousands of nodes. It may know a good design when it sees it, but it can't explain how to improve things. (Update 2023/03/20: a video by CGP Grey on YouTube does a fantastic job of not only explaining the training process, but why the “why” of a recommendation is so difficult.)
Without a line number to target or approach to change, API designers operating in such a system would resort to throwing things at the wall to see what sticks. And that is an infuriating way to work.
It might be possible to back up a step: rather than create the API description for validation, use the reinforcement model to create the API design from a prompt. And because the reward model trained the reinforcement model, that output from that should be a good design. However, with this approach, we're now trying to achieve API design specificity through the lossy interface of the English language. While I like me some words (2,000+ and counting), that's not a development paradigm many would be comfortable with.
Returning to 10k feet: Good Design is the Wrong Measurement
All of this has been an attempt to quantify whether an API design is "good". At the risk of having my API governance card revoked, I'll ask:
"What if Good Design isn't what we should optimize our systems for? What if, instead, it is a by-product of more meaningful metrics?"
In 2021, I had the good fortune of contributing a line of inquiry into the Postman State of the API report: could we find a similar correlation between high-performing API teams and the metrics for fast flow derived in the DevOps book, Accelerate. Nearly 30,000 responses later, the data was clear. High-performing API teams:
- Exhibited shorter lead times, or the time it takes to deliver a change to a customer
- Deployed more frequently
- Returned to regular operation faster when problems did occur
- Had fewer rollbacks and hotfixes
More of my argument is available in a different edition of this newsletter.
When we hear these terms, we almost always think of code releases. However, the same metrics apply to design. It is not about how 'correct' something is on the first try - something that is impossible. Instead, a "good" design emerges after numerous feedback cycles.
Optimizing our processes to produce "good" designs is a cul-du-sac. Applying metrics that focus our efforts on rapid, responsive change means that our API design will always be right where it needs to be.
Wrapping Up
No milestones this week as this is already hella long.
Lots of late-night head-scratching went into this newsletter. Thanks to the Patrons and Substack subscribers for offsetting the cost of caffeine. Those fine folks also help keep this endeavor free of paywalls or advertising for the benefit of all readers. Thanks!
That's all for now. Till next time,
Matthew (@matthew and matthewreinbold.com)