Service Meshes: Good Idea for a Tiny Few?
Net API Notes for 2023/11/30, Issue 227
The scene: Nearly any 2017 software development conference. After speakers namechecked Conway's Law and microservices, they'd pivot to service mesh evangelization. After all, companies that diligently decomposed their monoliths now had some very real challenges operationalizing all their numerous pieces. It seemed, at least to the conference-gencia (of which I'll admit I was a part), that service meshes like Istio, Linkerd, HashiCorp's Consul, Envoy, and more were the inevitable direction everyone would adopt. They were hot when I covered them in 2017 and again when I revisited them in 2019.
Fast forward to today, and service meshes are useful in some architectures. However, as a consultant allowed to peek under the hood at several large, well-known companies, I can confidently confide that service mesh implementation is the exception, not the rule.
But that's not just my experience. In August of this year, Gartner articulated the growing sentiment of many technology leaders:
"The hype around service mesh software has mostly settled down, and the market has not grown as much as was once anticipated. This raises questions about the usefulness and ROI of service meshes for most organizations." - Market Guide for Service Mesh
For those that don't speak C-suite, that's the analyst equivalent of a backhanded slap. Ouch.
What happened to service meshes on the road to inevitability? Are API gateways and service meshes redundant? And what role do service meshes have in today's software architectures? I cover those issues and more in this 227th edition of Net API Notes.
Service Meshes Are a Tech Solution to a Tech Problem
The Modern Software Architecture Creates Traffic
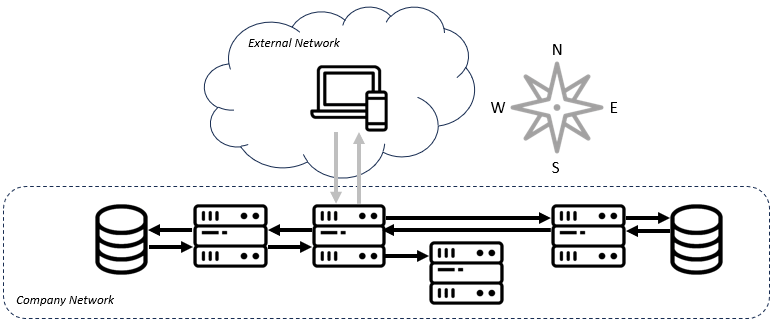
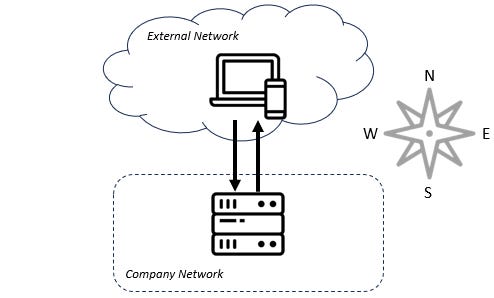
Before I define service meshes, it would be useful to illustrate the problem they're meant to solve. In ye-olden times (or like yesterday for all still so many folks), a request enters a company's network and is directed to a monolithic piece of software. That piece of software looks at the request and decides which response to return. This flow is often referred to as "north-south" traffic since in architectural diagrams like the one below, the traffic flows from the "north", or top of the diagram southward into the organization.
Traffic within a company's network is referred to as "east-west" traffic. As the number of services, particularly microservices, grew within software architectures, so did this internetwork traffic. Especially as workloads moved to the cloud, every bit of code had to increasingly know how to contact the other bits of code before marshaling a response.
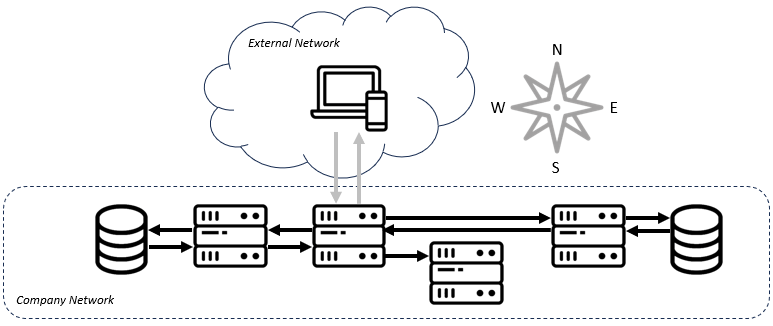
That "knowing", with scale, is non-trivial. A microservice might have to know which version of another piece of code it is compatible with, where to find it, and how to authenticate with it. It also needs to be a good neighbor to other pieces of code on the network. All told, developers were discovering that they had to repeatedly write a bunch of code that had little to do with the business problem they were solving. This included:
- Service Discovery
- TLS Certificate Issuing/Encryption
- Key Validation
- Advanced Routing like Circuit Breaking and Load Balancing
- Metrics Aggregation
Expecting each service development team to implement each of these things individually is not only redundant but also prone to inconsistency. Hence, the service mesh.
Service Meshes Comprise a Data and Control Plane
A service mesh attempts to solve the bulleted problems, above, by abstracting network concerns into a dedicated infrastructure layer. This code is fully integrated within each deployed application. This integration can be what's known as a sidecar proxy - when the service mesh implementation runs in containers in the same pod as the application containers. Or the service mesh can be integrated directly into the service or platform itself. In either case, this symbiotic relationship at runtime is referred to as the data plane; it intercepts calls between services and "does stuff" with that traffic.
To help manage this infrastructure layer, a set of processes, called the control plane, is provided by the service mesh. This is the administrative affordance that enables the behavior of the service mesh to be configured. The data plane calls the control plane to inform it of happenings going on, and the control plan provides an API for ongoing modification and inspection by the system owner.
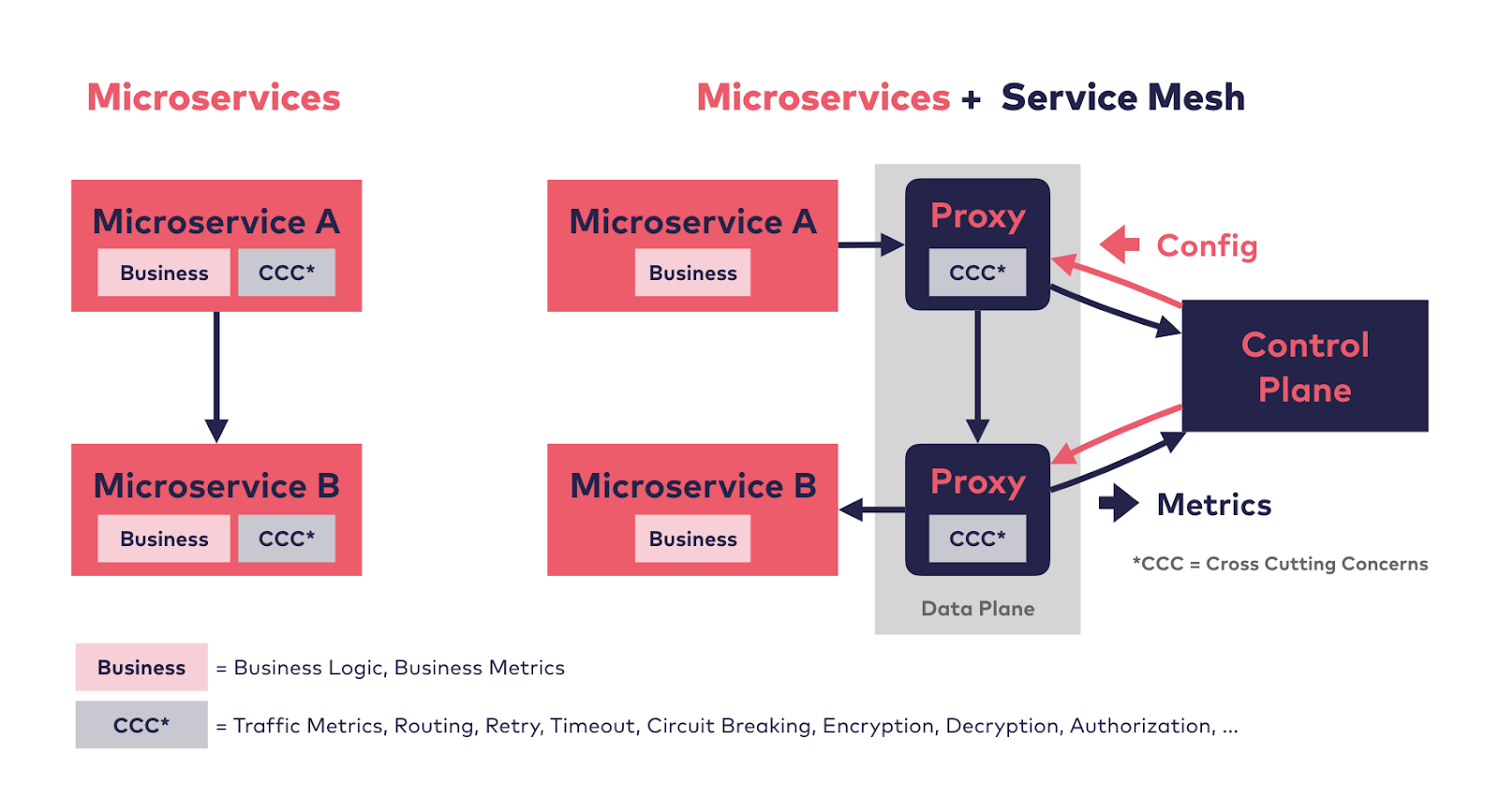
Service meshes attempt to eliminate the complexity, fragmentation, and security vulnerabilities inherent when repeatedly coding service-to-service communications. This focus on east-west traffic - the traffic between services - differentiates a service mesh from API gateways or ingress proxies. Those systems focus on north-south calls - calls from networks outside the company boundary.
Layer 7 Turns Out To Be a Powerful Control Point
Bright folks may ask, "Isn't this already what HTTP already does?" "Don't service meshes just add a layer of network management overtop an already existing network management layer?" Or, as analyst Michael Coté asks, "Is this what happens when people at higher layers of abstraction don't want to talk to their network admins?"
Many of you might be familiar with the 7-layer OSI model of the internet. It's a way of organizing all the various pieces necessary for two computers to talk to each other. Layer 7, or the topmost layer, is called the 'Application' layer. It is the point where applications can access network services. It turns out being able to programmatically influence networking, as opposed to ceding that work to a lower level, can be a great way to introduce additional logic into the system.
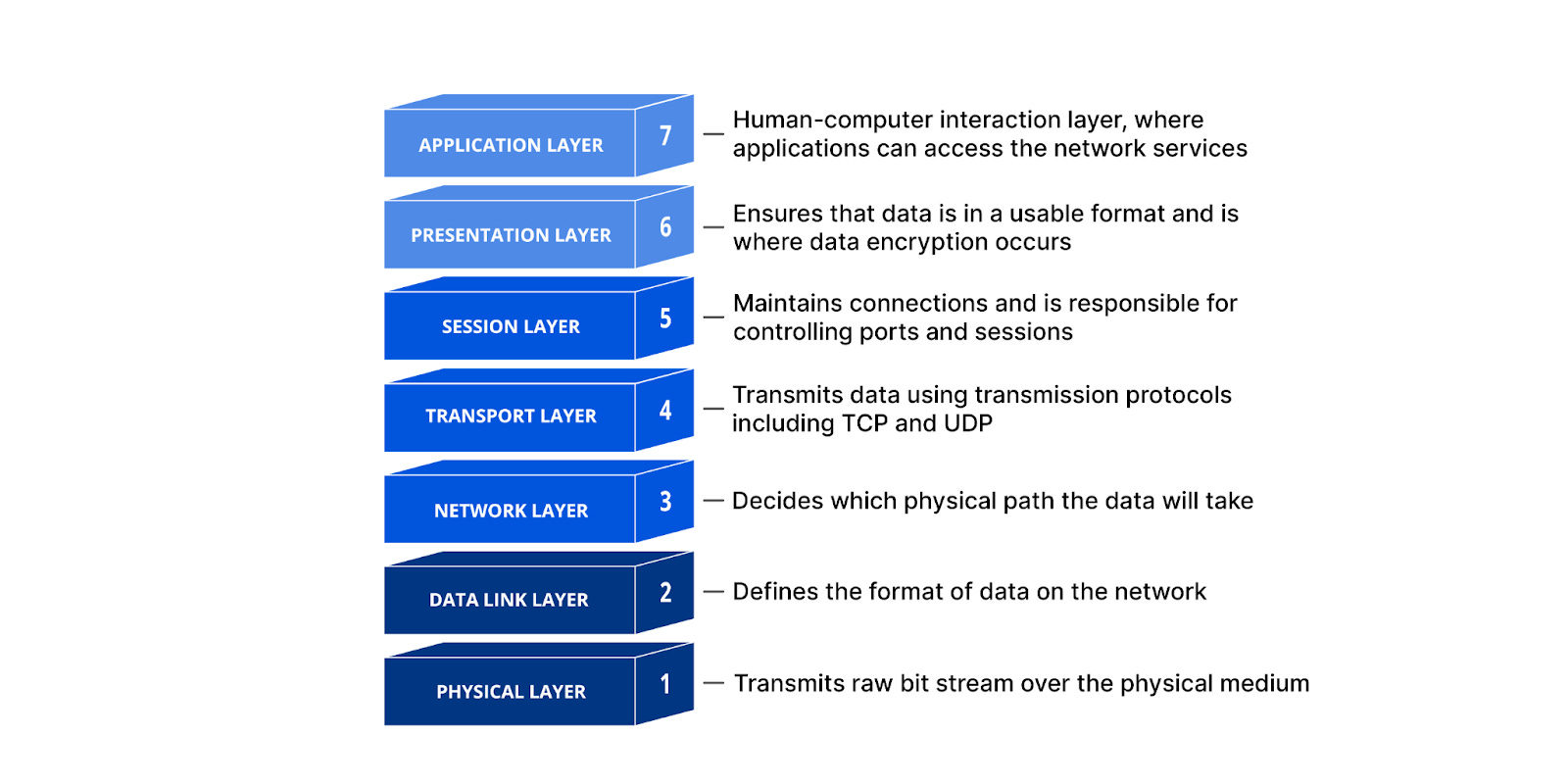
This is NOT like the 'BAD OLE DAYS' of the enterprise service bus (or ESB). Whereas those intermediaries were happy to slice, dice, and transform the contents of the message itself (and inflict untold suffering upon all debugging parties involved), service meshes have no such delusions of grandeur. The request payload remains as the application developer intended; there's no addition of extra fields to a JSON blob or transformation of an XML response to JSON with a service mesh.
Instead, the functionality performed by the service mesh is narrowly focused on operational concerns. Take this example provided by Linkerd maker, Buoyant:
"-if service Foo makes an HTTP call to service Bar, the linkerd-proxy on Foo’s side can load balance that call intelligently across all the instances of Bar based on the observed latency of each one; it can retry the request if it fails and if it’s idempotent; it can record the response code and latency; and so on. Similarly, the linkerd-proxy on Bar’s side can reject the call if it’s not allowed, or is over the rate limit; it can record latency from its perspective; and so on."
Useful!
Service Meshes Are Not Just Next-Gen, Decomposed API Gateways
It may be tempting to look at the proxying provided by an API gateway and see a lot of similarities with service meshes. The vendors of both API gateways and service meshes haven't helped the situation, either, as both frequently bleed functionality from one infrastructure into another.
As author and software architect Daniel Bryant points out, keeping the concepts separate best serves different use cases (emphasis mine):
"An API gateway handles user ingress traffic. This is often referred to as "north-south" traffic … An API gateway is typically deployed at the edge of a system.
"A service mesh handles service-to-service traffic, often called "east-west" traffic. This technology typically sits within a cluster or data center, and can also span "multi-cluster", joining two disparate clusters together at the network level.
"Although a lot of the underlying technologies involved are the same e.g. you can find the Envoy Proxy in API gateways and service meshes, the use cases are quite different. In particular, the way engineers interact with the two technologies and configure them is quite different. We often say that the "control plane" has different requirements for proxies being used as an API gateway or as a service mesh.
Implication of Service Meshes
Expecting developers to marry externally provided code to their babies creates some important implications, including:
- Whatever these data plane proxies are, they must be fast since service meshes add additional proxy hops to every call.
- These proxies are deployed in the same pod as the application and thus need to be small and light. That memory and CPU can't starve the application of resources.
- A robust cultural practice of deployment automation must exist to handle the vast number of proxies created by a service mesh. Manual administration of the control plane is not scalable.
Another service mesh consideration is that several of these projects are open source. While that means the price is right to get started (free as in beer), teams may quickly discover that they get what they pay for: a lot of unplanned work on the part of the company's service mesh advocates to research, integrate, debug, patch, and operate all the "free" components.
As alluded to in the Gartner report I previously mentioned, a lack of sufficient skills for effective engineering, administration, and operational upkeep of the service mesh significantly increases operational burden. These challenges only grow as deployed container pods and services scale exponentially, particularly in a multi-cloud environment.
Adrian Mouat, former chief scientist at Container Solutions, described the challenge this way:
"- running production apps and figuring out how to expose them securely requires understanding a wealth of different features that inevitably result in YAML files longer than most microservice source code."
The sentiment was echoed by long-time AWS employee and co-author of the XML specification, Tim Bray:
"I dunno, I’m in a minority here but damn, is that stuff ever complicated. The number of moving parts you have to have configured just right to get "Hello world" happening is really super intimidating."
Service Meshes Aren't Inevitable
This increased complexity, requiring specialized, centralized coordination and management, has subsequently led software developers to consider alternatives.
In some cases, this has meant a re-evaluation of whether microservices were necessary to begin with. The most surprising example, perhaps, came in early 2020. As documented by Christian Posta, Istio - one of those open-source service meshes - decided that their dozen (or so) microservices created too much "operational complexity". As a result, they re-architected the service as a monolith.
Maybe microservices are still useful divisions of labor within your software org. However, nothing says the communication between them has to be synchronous. Event-driven (or reactive) microservices have their own nubbins. However, networking isn't one of them and may be a viable service mesh alternative.
Going further, perhaps the galaxy brain approach to server message routing may be to get rid of the servers entirely. This is what serverless proponents like Simon Wardely, the Wardley maps namesake, advocate. He has suggested that Function-as-a-Service (Faas)/Serverless will "ultimately replace Kubernetes as the de facto standard runtime for distributed applications" (and subsequently minimize, if not replace, the need for service meshes). Institutions, such as the BBC, have embraced this approach for most of its online architecture.
Conclusion
In the future, especially for enterprise customers where performance is not paramount, service meshes may exist, but they'll just be embedded in the underlying platform, hidden from developers. Red Hat OpenShift, for example, integrates Istio under the covers. AWS App Mesh and Google Cloud Platform Traffic Director are similar efforts integrating service mesh functionality into their respective clouds.
As Charles Humble pointed out in The New Stack, work is also being conducted to reduce the networking overhead introduced by a service mesh. Some of the most promising is the work by the Cilium team, which utilizes the eBPF functionality in the Linux kernel for what it calls "very efficient networking, policy enforcement and load balancing functionality."
Ultimately, there is no one correct answer, and context is king. Ivan McPhee wrote an impressively detailed overview of service meshes in the latter half of 2023. He characterized approaching service meshes as follows :
"Avoid adopting a service mesh based purely on consumer trends, industry hype, or widespread adoption. Instead, take the time to understand the problem you’re trying to solve. Explore the potential tradeoffs in terms of performance and resource consumption. Evaluate your support requirements against your in-house resources and skills (many open-source service meshes rely on community support). Once you’ve created a short list, choose a service mesh—and microservices-based application development partner—that works best with your software stack."
Milestones
- The US Air Force announced a new "API-First" initiative.
- At AWS re:Invent 2023, the conference whose spelling I have to look up every time I write it, Amazon re-announced Bedrock. Bedrock is a managed service that exposes several AI models via an API.
- More bad news for Okta - what was once positioned as a breach affecting a minority of customers has now been revealed to be far more extensive.
Wrapping Up
I hope those who celebrate the recent Thanksgiving holiday had a good one! This is a special time of year for a variety of reasons. From a newsletter standpoint, fitting posts through narrowing publishing windows becomes very challenging. It seems like only yesterday I released "Eran Hammer's OAuth 2.0 'Road to Hell'", the second ¡APIcryphal! piece for paid subscribers. However, the way the weeks line up, I need to drop the third in the series: Anne Thomas Manes 2009 declaration that "SOA Is Dead" ASAP to fit everything in before people disappear at the end of the year.
I am incredibly grateful to the paying subscribers who make this preservation work possible. They also ensure that Net API Notes editions remain free of paywalls, advertising, and list selling. There's also an upcoming collaboration in January for which I am just now seeing the art concepts for. I think you're going to enjoy it. More soon!

If you want to support Net API Notes, head to the subscription page. For more info about what benefits paid sponsorship includes, check out this newsletter's 'About' page.
Till next time,
Matthew (@matthew in the fediverse and matthewreinbold.com on the web)