The Necessity of Naming in APIs
Net API Notes for 2023/09/20, Issue 222
You've probably heard the joke - you know, the one from Xerox PARC and Netscape legend Phil Karlton:
"There are only two hard things in Computer Science: cache invalidation and naming things."
The challenge is particularly acute for API designers. Whether we're talking about the resources themselves, the objects within, or affordances offered by pagination or filtering controls, naming should convey the API producer's mental model to many consumers with minimal fuss. Yet, start talking about integration experiences at any meetup or conference, and the horror stories about decoding unknown abbreviations, tracking down subject matter experts (SMEs), and cross-compiling support documentation abound.
To lower the cognitive overhead required to integrate with your API, you must consider naming design issues. It is the #1 thing that an API producer can do to improve a design, always. It is also one of the most grokable activities that anyone on the API production team can participate in. However, despite these benefits, too often naming is an afterthought. What gets shipped is a series of first drafts and best guesses.
In this edition of Net API Notes, I'll illustrate why naming is a deceptively simple task, speak glowingly of a book that goes deep on the topic, and end with why the well-intentioned data dictionary usually ends in tears. That, and more, below.

What Is In A Name
Naming Things Is Difficult For a Variety of Reasons
Nick Tune is a software consultant and author. Several weeks ago, when describing the challenges of finding good names while domain modeling, he shared several, sometimes comical, contradictions inherent in the language we use to communicate:
"A wooden table is made from wood.
A glass table is made from glass.
Why is a coffee table not made from coffee?
"This is actually relevant to domain modeling: sometimes we name things after their properties and sometimes their purpose.
"And sometimes we're talking about the same physical thing from the perspective of a different subdomain where it has a different name.
"These factors also play a role in determining how we decide to shape boundaries."
While Nick was talking about domain modeling, his points are equally valid for the names we use in an interface. Let's take a hypothetical API we want to use. The call to retrieve an array of resources lists a query param entitled "filter". Without subsequent information, how would you assume the filter behaves? When you pass a value to the "filter" query param, does the API:
- Only returns items that match the passed value, filtering values that are not equivalent?
- Returns all values other than those matching the filter?
It may not be obvious. Do you name the filter after what it lets through or what it keeps out? Unfortunately, real-world examples don't clarify the situation. For every "air" or "coffee" filter - instances where the filter allows the named item to flow through - there's a "spam" filter counter-example, a situation where the named entity is filtered out.
On its own, "filter" is not sufficient to convey how the affordance behaves. Sure, a line or two describing how the query parameter operates could fill in the missing context. Or we could take a few more cognitive cycles in design and find a more expressive name.
The 'Accounts API' Naming Might Not Be As Obvious As You Think
But problems lie not only at the field level. From that same Nick Tune thread:
"I was involved in a project at Lufthansa many years ago, and during the modeling of "Check-In" software, they had 7 different meanings of the word "Flight" (their primary business purpose) but nowhere was it explicitly defined or using different names.
From an Identifier, to plane in the air, to scheduled in the future, to completed, and more.."
One of the first domains companies attempt to shoehorn into one of their first APIs is "Accounts". After all, everyone has to deal with Accounts, right!? Unfortunately, the 'Account' domain in software modeling is deceptively complex, and its interpretation can vary widely based on department, lifecycle, and geographical perspectives (among others). Consider:
The Departmental Perspective:
Sales/Marketing might see an account as a potential or existing customer. They would expect an Account API to focus on details like lead source, potential revenue, and contact history.
Finance views an Account as a billing entity. They would expect the API to emphasize credit limits, payment history, and outstanding balances.
Customer Support would prioritize support history, ticket status, and service level agreement information in their Account API integration.
The Lifecycle Stage Timing:
Prospective Accounts, or potential customers that haven't made a purchase yet, would have different expectations than-
Active Accounts, which may have a different set of actions that can be performed on them than-
Inactive Accounts, or customers with no recent activity, which are distinct from-
Archived Accounts or old accounts that are no longer active but need to be stored for historical purposes.
The Geographical Context:
Different regions have different regulatory requirements. For instance, data handling in the EU is influenced by GDPR, which might affect which data is surfaced via the interface, along with affordances on what can be done programmatically to the data.
There may be different names for the same concept; while 'Accounts' is used stateside, other areas might prefer the term 'Ledger'.
In other words, while the term 'Account' might seem straightforward and only possesses one interpretation in our head, a shift in perspective may result in a very different set of expectations; expectations that subsequently impact the use cases the API serves.
'Payments' is another example I often see within companies that immediately triggers several questions for me. Is the "Payments" API how we can accept money electronically to purchase a good or service? Or is it the historical record of all sales made in a given period? The API producers may have understood their use cases clearly, and felt it was covered with the word "Payments". But while the use cases served may have been clear to them, it isn't to me without further reading.
There's A Book for That
These aren't occasional edge cases. The challenge of naming things in software is so significant that entire books have been written on the topic. A recent one that I love is Naming Things: The Hardest Problem in Software Engineering by Tom Benner.
On first blush, Tom's recommendation that names should be "understandable" -or that a name should describe the concept it represents- seems self-evident. But it is in the subsequent breakdown of what makes something "understandable" that we get a better feel for applying the advice to our API designs.
For example, if a key within a JSON response appears as "dir", should we expect the value to be a direction? Or a directory? We have a poor name whenever we have to reach for additional context to answer these questions. Similarly, while "o" or "org" might save a few keystrokes, a dictionary term like "organization" has better comprehension and recall than invented jargon.
Avoiding acronyms is another nuance within understandability where I've had several conversations. At what point does something like 'FDIC' go from being a shortcut to a well-understood concept safe for naming? Does it make sense to require an API designer to spell out "federal_deposit_insurance_corporation" when everyone within the domain only knows it as "FDIC"? What about other acronyms like "pin" or "atm"? If abbreviations like "org" are problematic, should a design use an acronym like "atm"?
Our rule of thumb we settled on in our practice was to do a Google search. If either the abbreviation or acronym for the concept appeared "top of the fold", we agreed that it was common parlance. This kept internal team shortcuts or localized jargon out of designs but still provided some sanity for terms that "crossed over" into regular use.
In addition to "understandability", Tom also goes into significant nuance on:
- Conciseness (Using "Albums" rather than "SongCollections")
- Consistency (Referring to "Customer" throughout a design, rather than "User" in one schema, "Account_Holder" in another, and "Buyer" in a third.)
- Distinguishability (Using "Course" instead of the overloaded and potentially misunderstood "Class")
An insightful portion of the book discusses the tradeoffs confronting a designer. Going back to the earlier example, we might attempt to use "dir" as a name that appears within a design, citing it as "concise". However, the understandability of using a full dictionary word outweighs the few characters we can save.
A successful API design is understood by consuming developers with a minimal amount of overhead. Proper, consistent naming reduces ambiguity, pivotal in promoting comprehension. Applying the principles described in Naming Things is crucial for anyone designing interfaces.
The Data Dictionary Applied to APIs is a Good Idea Taken Too Far
With all this naming importance, with entire books on how to do it correctly, well-meaning API folks may look at their data counterparts and the work they do in data warehousing. After all, if those people can create a single source of truth for their data names, could that also be applied to APIs? Can we increase consistency and reduce disambiguation if we just name all the things and then regularly draw from that work?
Defining a set of "allowed" terms that teams should use is known as a data dictionary or data catalog. While it might start from a place of good intentions, in my experience, it quickly turns into tedium and contentiousness when applied to APIs for several reasons:
- Just deciding who can define names is a power exercise that some may see as threatening; as a result, the simple task of choosing who is "in the room where it happens" can lead to conflicts.
- After selection, those creating the dictionary face a complex challenge: large enterprises may have dozens, even hundreds of domains. Defining and managing concepts is not trivial.
- Furthermore, these enterprises are not greenfield. Any naming exercise contends with existing systems that were built without consistent naming conventions; aligning them with any new dictionary represents either significant rewrites or the creation of an abstraction layer. Not to mention the increasing number of 3rd party inputs, each with their own perspective.
- Similarly, different departments or business units might have their localized language. Integrating these into a unified enterprise data dictionary will encounter resistance or discrepancies, especially if different departments have different sensitivities or needs.
- Even if a dictionary is attempted, it will likely to be outdated immediately upon completion. Businesses are not static. As their needs evolve, so do their dictionaries. Trying to keep all stakeholders aware and adhering to these changes (particularly when those changes connote schema versioning), is daunting.
Because of these reasons, data dictionaries and data catalogs, at least for APIs, end up being a large maintenance burden for little actual value. Rather than expending effort on a dictionary to be applied to API schemas, API designers' time is better spent maintaining a well-organized and documented API definition. Whether that is via OpenAPI or another specification, these descriptions should be easily discoverable within an API catalog. When possible, developer touchpoints - like the catalog - should promote well-designed efforts and encourage other designers to "borrow" naming and schema cues that apply through their use cases. Reusable elements should be a prompt away within the IDE while designing. By kickstarting new designs from existing good designs, doing the right thing (consistency in naming and structure) becomes the easy thing. Rather than have a dusty dictionary on the corporate CMS's shelf, an API's lifecycle and tooling environment should proactively promote eventual consistency throughout an API design's naming.
Conclusion
In January 2016, the Swagger specification was renamed the OpenAPI Specification (OAS). Fast forward and nearly eight years later, and we still see conference speakers (!) misuse the terms. If you want to improve your designs, improve your naming. After all, the first name you give something tends to be the one that sticks.
Milestones
- Stoplight was acquired by Smart Bear. Lots of pieces are now under the same tent. What happens to the Swagger brand?
- API security and monitoring software companies APImetrics and Contxt intend to merge.
- WunderGraph launched Open Federation, an 'open specification for building federated GraphQL APIs'. Subsequently, they're offering WunderGraph Cosmo, a solution for building GraphQL APIs on top of Open Federation.
- Duolingo had 2.6 million records scraped from a vulnerable API earlier this year and released to a hacker forum. In January of this year, someone was trying to sell this data for $1500. Data included name, username, and learning process. The dataset also included user's email addresses, which is not considered public information. Despite detailed write-up ups of the attack having been online for some time, the problematic API is still available.
- Speaking of API security, Troy Hunt of Have-I-Been-Pwned fame has a new article on how to use Cloudflare's Turnstile to combat API bots.
Wrapping Up
At the close, I want to warmly welcome Allan, the newest paid subscriber to this newsletter. Supporters like Allan ensure that this material remains ad and paywall-free for everyone to enjoy.
Further, paid subscribers encourage bigger and more expansive explorations into the API space, like building a dataset of API job listings for subsequent analysis and reporting. At the end of the recent product management follow-up, I mentioned that some of this data is locked behind an outrageous $800-a-month gate. With some sleuthing (and a fair amount of programmatic duct tape) I've got a working solution on the order of $50-a-month; not trivial, but more (mostly) covered by the current paid subscribers.
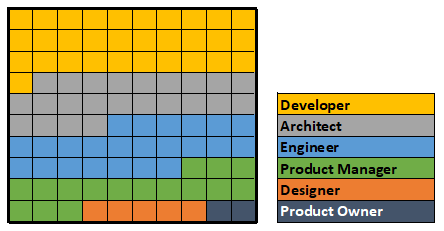
Of the thousands of listings I have so far, there are already some fascinating breakdowns. And, like much of the best analysis, answering initial questions, like "What API roles are currently being sought?" (above) leads to additional questions:
- What are the responsibility differences between API "Developers" and "Engineers"? And do those differences translate to different benefits (mainly salary)?
- How are the "Product Manager" and "Product Owner" roles differentiated? Are there gaps in my recent post?
- What tool stacks experience is sought?
- With a large enough sample, can we summarize and generate usable job description templates for use during hiring and performance management activities?
Lots of work to do for an upcoming edition of Net API Notes. But the initial results partially funded by paid subscribers look promising.
If you'd like to become a paid subscriber, head on over to the subscription page. For more info, check out the revised 'About' page.
Till next time,
Matthew (@matthew on the fediverse and matthewreinbold.com on the web)