From Shared Knowledge to Private Answers
Stack Overflow turned programming into a shared conversation. AI turns it into a private loop. The answers are faster and more tailored—but something essential may be getting lost in the process. Net API Notes for 2026/04/30, Issue 259.

This past January, while I was otherwise occupied, a news and analysis website called Dev Class published an eye-opening accusation:
Stack Overflow was dead, and AI killed it.
Accompanying the article was a graph that, indeed, was the opposite of an up-and-to-the-right success story.
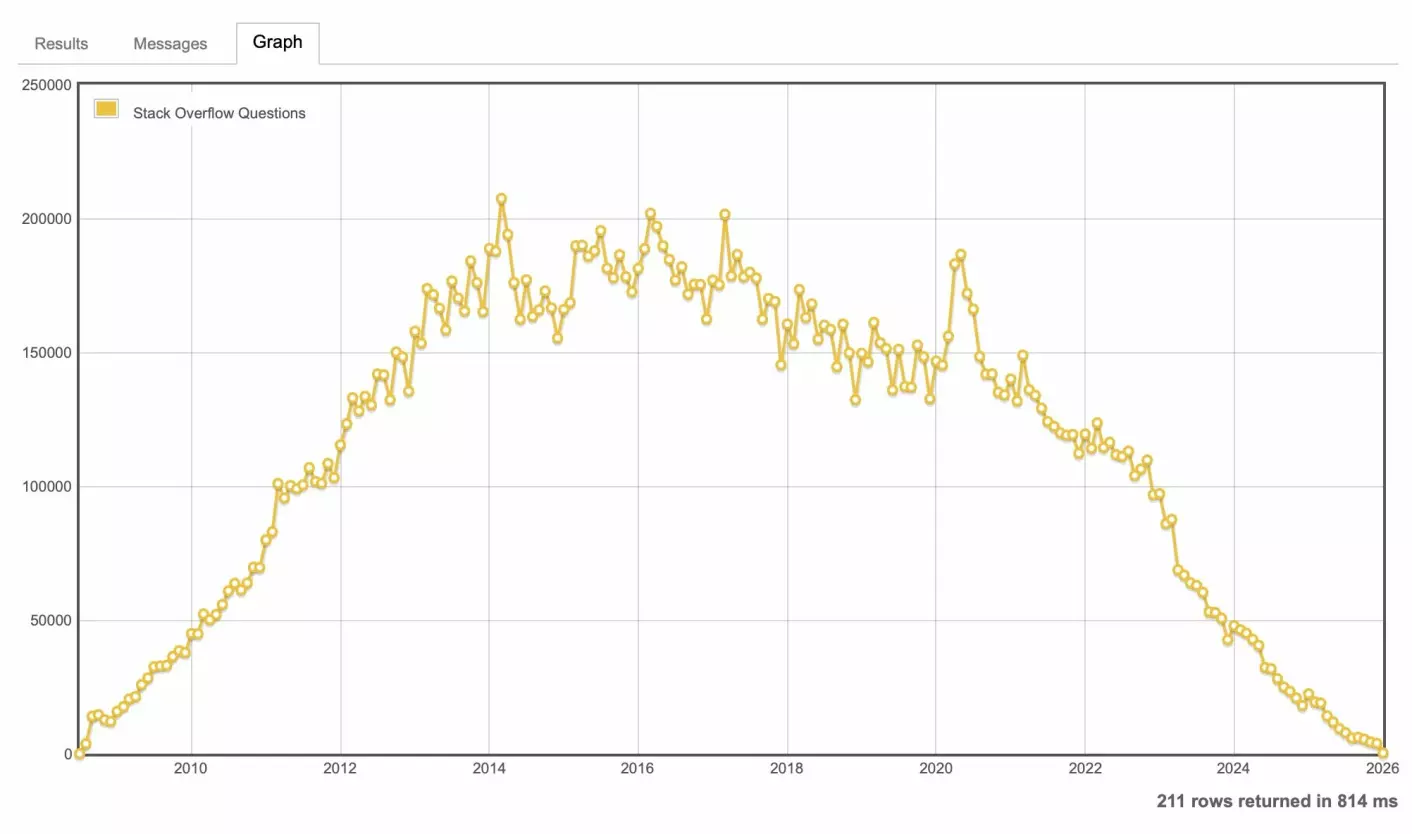
Launched during the height of the crowdsourcing, or "wisdom of the crowds" fever, Stack Overflow seemed like a fantastic idea from two genuinely decent-seeming software people, Joel Spolsky and Jeff Atwood. It was meant to be a more egalitarian alternative to existing programmer resource sites, which - even already in 2008! - were already high-noise, low-signal affairs. Their solution? Combine a Q&A site with community voting and editing.
At its peak in the 2010s, Stack Overflow wasn't just a useful site; it was software development's shared reference. If you wrote code, you were there, whether you intended to be or not. Search for any error message, and the top result was almost guaranteed to be a Stack Overflow thread. Its conventions - accepted answers, code snippets, canonical duplicates - became a shared language across teams and companies.
Stack Overflow outcompeted predecessors like Google Answers and Experts Exchange not just by being free or better organized, but by achieving critical mass: more questions, more answers, more eyes, more edits. The result was a self-reinforcing loop where the best place to find an answer was also the best place to leave one. The net effect was that "how to be a productive programmer" and "knowing how to navigate Stack Overflow" were often synonymous.

In episode 300 of the Stack Overflow Podcast, Spolsky outlined the vision for "human" social software. That vision outlined how voting and a community moderation model- two essential pieces of the platform's reputation-based curation - might be applied to other topics like design, ethics, and even civic engagement. The advantage of this model was that it prioritized high-quality knowledge over popularity or commerce.
In May of 2023, Stack Overflow laid off 10% of its staff. However, that did little to slow the rapidly receding traffic. Stack Overflow fired an additional 28% of its staff that October. At the same time, it began signing data partnerships. Two of these partners, Google and OpenAI, intended to use the entirety of Stack Overflow's community-created data to further train AI models. Contributors began sabotaging their posts in protest.
Like most Stack Overflow users, my interactions with the site were decidedly mixed. On the one hand, I did find legitimate answers to my questions several times. But, on the other hand, I'm sure I'm not the only one who had their issue closed prematurely because it was a "duplicate", had their approach ridiculed, or were told to "RTFM".
Then there was the inference tax. Even when I uncovered answers that were approximately what I was looking for, there was the tedious translation of that specific solution to my problem that I had to perform - often with a fair amount of trial and error.
So why did the generative AI approach win?
Saying that software practitioners abandoned Stack Overflow for generative AI tools because of speed is an oversimplification. The truth is that tools like Copilot, Claude, Gemini, and ChatGPT represented a complete collapse between a developer's intent and the execution. If Stack Overflow was a library where you had to find the right aisle, shelf, and then book reference before (maybe) finding an answer, generative AI was the paired programmer that just told you the answer.
That sea change in developer habits boils down to a handful of primary drivers:
- Radical Immediacy: Stack Overflow is an asynchronous community. One posts a question and waits - sometimes for minutes, often hours, and occasionally forever - for a human to respond. AI is instantaneous, by comparison.
- Hyper-Specificity: On Stack Overflow, one looks for an answer "vaguely shaped" like the problem they have. They then have to pay the "inference tax" to map their solution back to their own context.
- Contextual Richness: Related, because these models can ingest the surrounding code, templates, and even architectural constraints, the response isn't just a snippet; it's a tailored fit.
- Native Embedding: Rather than leaving the IDE to wrestle with Stack Overflow's increasingly complex UI or dodge a "duplicate" flag from a grumpy moderator, the assistance is where work already happens.
I say all this, readily acknowledging that the responses provided by generative AI aren't the right answers; as statistical models, they only provide what is probable. This would conceivably be a positive for Stack Overflow's "human" social software. However, for most users, the "rightness" is secondary to the momentum. The tight feedback loop of asking for a thing, trying a thing, and repeating until it compiles far exceeds the value of waiting for a canonical, verified answer from the get-go. For the modern developer, a "200 OK" achieved through iterative guessing is more attractive than a slow, lectured "lesson" on why their question was poorly phrased.
When knowledge acquisition takes a backseat to workflow optimization
The tragedy of this "win" is that while we've eliminated the friction of the search, we've also bypassed the learning process.
Puzzling together a Stack Overflow answer was, admittedly, inefficient. But that inefficiency was where the "know-how" happened. By translating a general solution to a specific problem, one wasn't just fixing a bug; one was building a mental model. Today's interaction is different. When a developer asks an AI for a solution and blindly applies the result, they haven't learned the why; they've simply learned how to pull a slot machine lever. They are more productive today, but no more capable tomorrow.
This isn't just an individual loss; it is a systemic one. Stack Overflow and, to a lesser degree, "Tech Twitter", functioned as a shared commons where "best practice" could be hashed out in the open. Consensus wasn't just given; it emerged through the push and pull of public discourse. Sometimes in fits and starts, often contentiously.
Without this digital commons, I'm concerned how common practice will emerge. When everyone is off in their own private, AI-glazing silos, we lose the "co-evolution" of standards. We are trading a messy but shared language for a collection of private dialects. This is a future where "best practice" is whatever a statistical model happens to parrot for us in the moment.
It doesn't have to be this way. In theory, an AI could be a powerful, personalized tutor, guiding a developer through the nuances of, say, API design. I've talked about this before. But in a world governed by Jira velocity and "ship-it" cultures, I doubt any but a tiny minority actively pursue this approach. The fact is, most are content to use genAI as a well to draw on, not a mirror to grow from. And while the output increases, the craft quietly atrophies.
I'm quick to note that AI didn't create the output-over-outcome problem. But it sure poured gasoline over what was already a management tire fire.
When Information Is Plentiful, Judgment Becomes Scarce
Losing Stack Overflow doesn't mean we're losing knowledge. But it does mean we are losing a means for developing judgment.
The platform, for all its prickly moderation, forced users to navigate ambiguity. It required people to weigh multiple, often conflicting, human perspectives and decide which one applied to our unique constraints. genAI, by contrast, offers a path of least resistance. It'll offer up something that looks "right enough" to ship, but API design is fundamentally about the trade-offs a statistical model can't compute.
A successful API design isn't decided by who can generate the endpoints the fastest. It will be decided by who can recognize when those endpoints shouldn't exist at all.
API judgment during this AI age looks like this:
- The Power of "No": Resisting the urge to expose every field just because the AI made the API description, documentation, and code generation trivial.
- Impact over Output: Prioritizing the long-term stability of the consumer experience over the short-term speed of the producer's Jira ticket.
- Cost Accounting: Recognizing that every generated line of code is a liability that requires a human to defend it three years from now.
- Design Review Reframed: In a world where anyone can glaze a bad idea with AI, design reviews need to change. Rather than focusing on the what (the OpenAPI description, or "spec"), design reviews should focus on the why (the business cases and decision log). If a developer can't explain the trade-offs they made, the design isn't finished.
But, perhaps, the best application of judgment is recognizing that the "system" - your IDE, your company's velocity metrics, the third parties rushing to add AI to their feature set - will not teach you to be better at what you do. They are designed to remove friction, and friction is where learning happens. If you want to maintain your craft, you must move from being a consumer of solutions to a curator of logic.
This requires a manual, intentional learning loop. I understand that too many companies see "tokenmaxxing" future readiness; said another way, employees are being mandated to use AI. That's grossly misguided, but so be it. For those having to play along:
- Generate: Let the AI provide a solution.
- Dissect: Break the solution apart. Identify the dependencies, the assumptions, and the potential failure points.
- Reconstruct: Close the AI tool. Rewrite the solution from scratch using only your own understanding and memory.
- Compare: Look at the delta between the two. What did the AI miss? What assumptions were wrong, and what did they lead to? What did you miss in your reconstruction, and why?
If you care about your craft, you cannot outsource your learning to a tool designed to bypass it. Write the design documentation before you prompt the code. Compare three different architectural approaches before settling on the most "probable" one. In a world of automated output, the most valuable thing you can offer is original, defended thought.
Wrapping Up
I'm very much looking forward to Spring. Here in the Twin Cities, we are about to turn the calendar to May under frost warnings. The garden sprouts I planted mid-March are ready to go, and I'm ready for my office to stop smelling like damp earth all the time. At least the chickens seem to be having a good time.
Let's hope April showers (and cold) brings May flowers.
Till the next edition,
Matthew (@matthew in the fediverse and matthewreinbold.com on the web)